Below are a few of the latest posts in my blog. You can see a full list by year to the left.

Delivering enterprise-grade access control for virtual chunks - surprisingly subtle!
Access billions of chunks of satellite imagery as a single Zarr store, without copying any data!
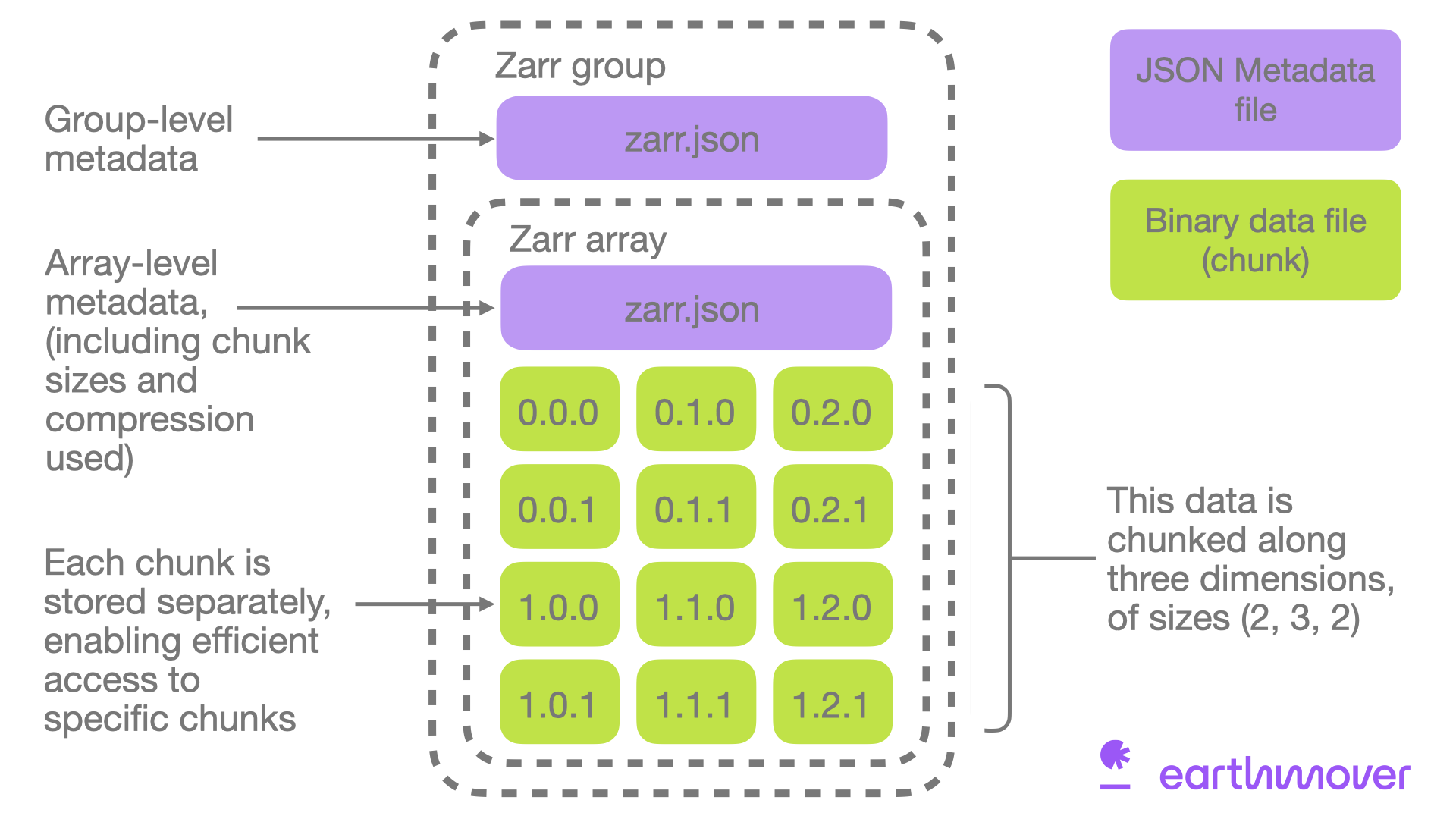
The article I wish I could have read back when I first heard of Zarr in 2018. Explains how object storage and conventional filesystems are different, and the key properties that make Zarr work so well in cloud object storage.
Imagine being able to visit one website, search for any scientific dataset from any institution in the world, preview it, then stream the data out at high speed, in the format you prefer. We have the technology - here's what we should build.
How xarray's new DataTree feature came about, and thoughts on how public agencies can support the open-source scientific software that they depend on.

Cubed was designed to address the main problems with Dask, so I integrated it with Xarray.
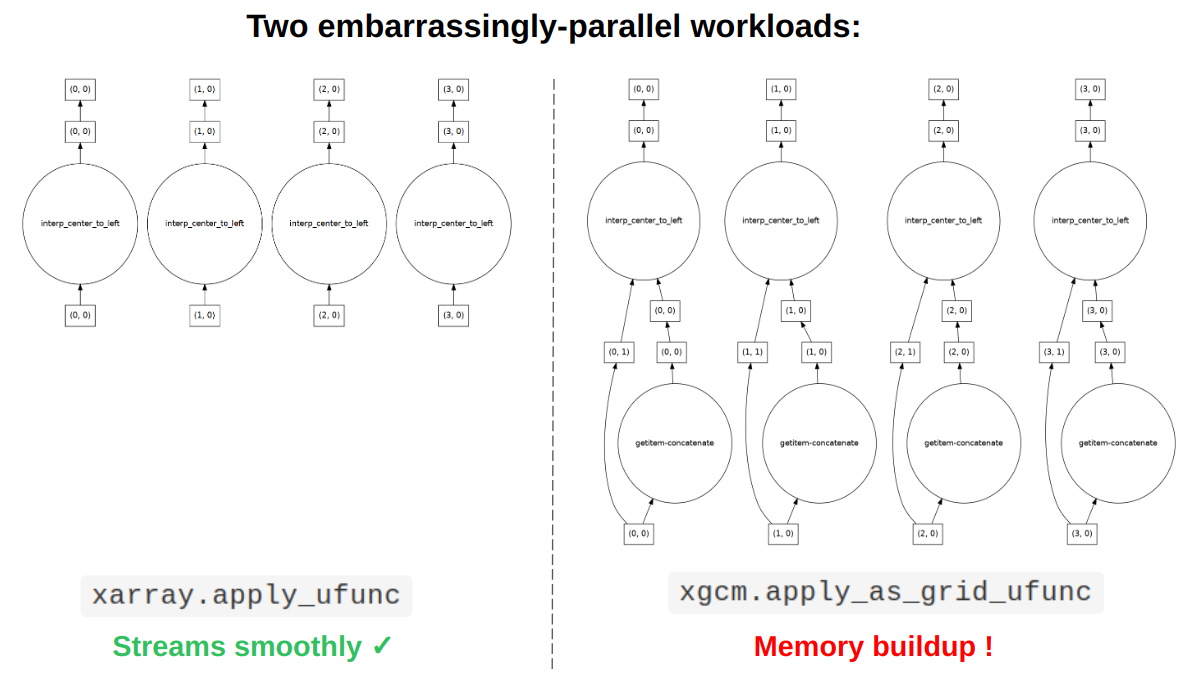
Dask's distributed scheduler algorithm got a major fix after we tested its' limits on a huge oceanography analysis problem.

All scientific computations involve units, so let's make our analysis software aware of them.
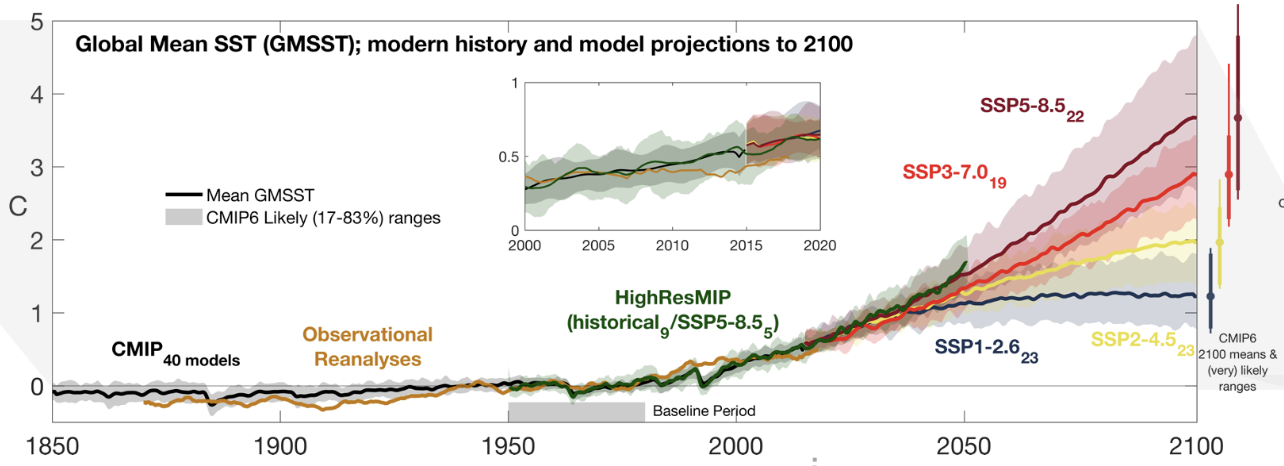
Analysing CMPI6 data as a motivation for xarray DataTree.
Geoscientists have already solved many of the software problems plasma physicists still struggle with - they should just use the same solutions.
Calling out pseudoscience claiming that societal collapse due to climate change is inevitable.

Thought's on Oxford University's fossil fuel divestment motion.

Solving the simplest possible epidemiological model of the spread of COVID-19.
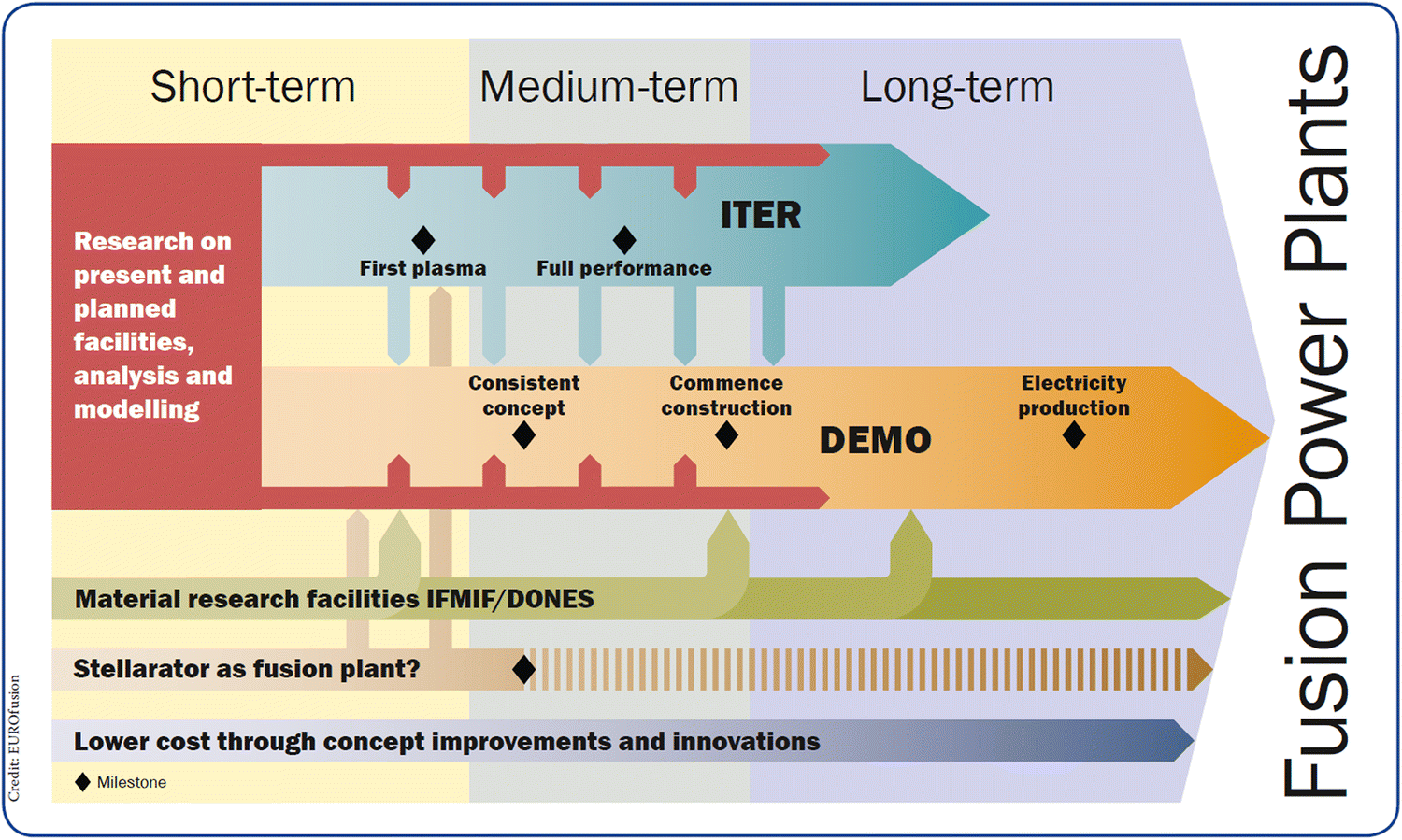
Don't let politicians use funding for nuclear fusion research as greenwashing.